离线接入
概要
本流程主要说明把离线数据实时导入到
Tindex
1. csv文件导入
导入过程步骤:
第一步:找MiddleManagers服务IP
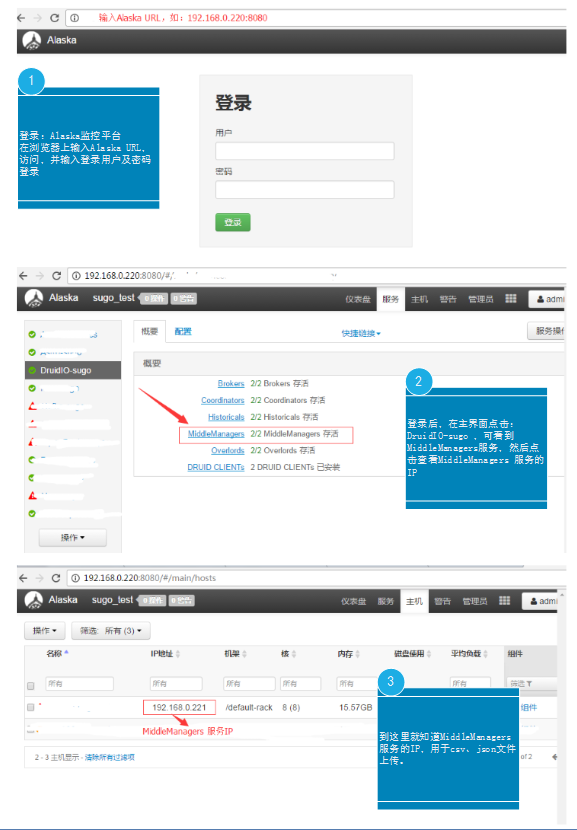
第二步:到MiddleManagers服务器上传本地数据文件、任务json文件
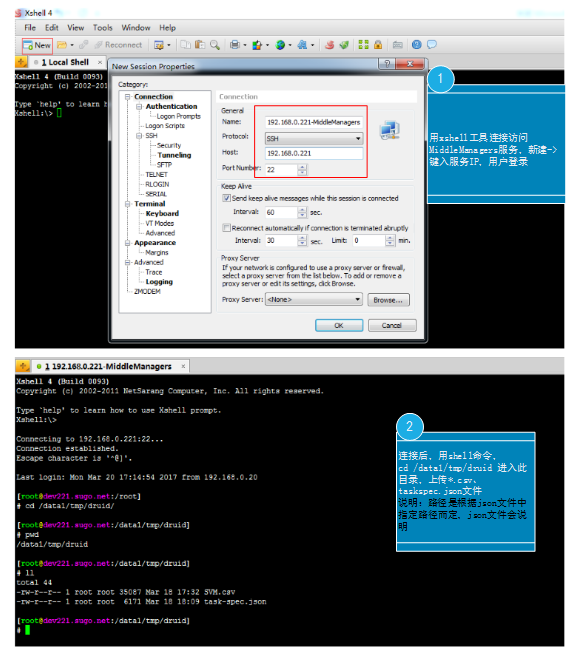
- 通过shell登录后,输入命令:cd /data1/tmp/druid
注: /data1/tmp/druid 根据 taskspec.json 文件实际路径决定
第三步: 创建、编辑、保存taskspec.json文件:
在 data1/tmp/druid 目录下,vim taskspec.json ,将下面json配置说明内容拷贝,然后点击键盘 ESC 按键退出编辑, 再输入 wq 命令退出并保存。

第四步:执行命令上传csv文件
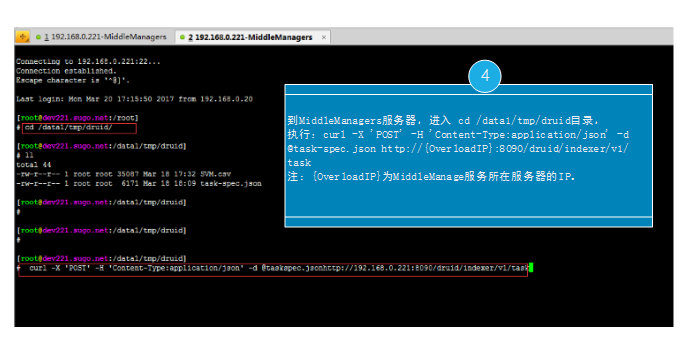
csv文件上传, 在shell工具登录:MiddleManagers服务器, cd /data1/tmp/druid 目录下,执行:
curl -X 'POST' -H 'Content-Type:application/json' -d @csv-task-spec.json http://{OverlordIP}:8090/druid/indexer/v1/task
overlordIP: druid的overlord节点ip地址
csv-task-spec.json task配置文件,详见下文
第五步:查看csv文件上传task的日志信息。进入overlord服务的任务列表页面,查看数据导入情况。
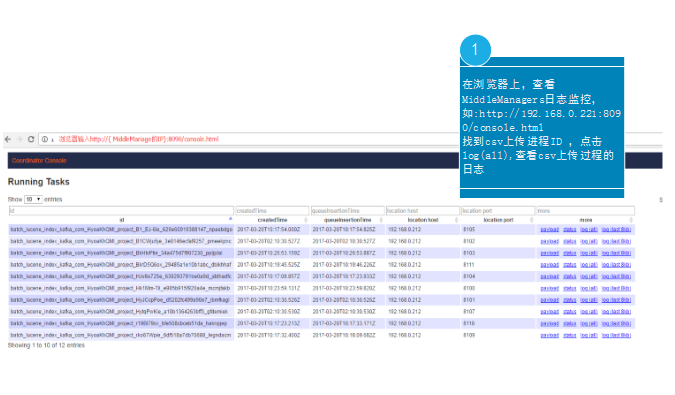
http://{overlordIP}:8090/console.html
overlordIP: druid的overlord节点ip地址,如果有多个overlord,必须指定leader的ip.
第六步:在需要停止task时,可以发送如下http post请求停止task任务
curl -X 'POST' -H 'Content-Type:application/json' http://{overlordIP}:8090/druid/indexer/v1/task/{taskId}/shutdown
overlordIP: druid的overlord节点ip地址,如果有多个overlord,必须指定leader的ip.
taskId: 在
http://{overlordIP}:8090/console.htmltask详细页面对应 id 列的信息
csv-task-spec.json详细配置如下:
{
"type" : "lucene_index",
"worker": "dev224.sugo.net:8091",
"spec" : {
"dataSchema" : {
"dataSource" : "test_10million",
"parser": {
"type": "string",
"parseSpec": {
"format": "csv",
"timestampSpec": {
"column": "dealtime",
"format": "yy-MM-dd HH:mm:ss.SSS"
},
"dimensionsSpec": {
"dimensionExclusions": [],
"spatialDimensions": [],
"dimensions": [
{
"name": "old_card_no",
"type": "string"
},
{
"name": "gender",
"type": "string"
},
{
"name": "birthday",
"type": "string"
},
{
"name": "mobile_province",
"type": "string"
},
{
"name": "mobile_city",
"type": "string"
}
]
},
"listDelimiter": ",",
"multiValueDelimiter": "\u0002",
"columns": [
"dealtime",
"old_card_no",
"gender",
"birthday",
"mobile_province",
"mobile_city"
]
}
},
"granularitySpec" : {
"type" : "uniform",
"segmentGranularity" : "MONTH",
"intervals" : ["1000/3000"]
}
},
"ioConfig" : {
"type" : "lucene_index",
"firehose" : {
"type" : "local",
"baseDir" : "/tmp/test/aaa",
"filter" : "*",
"recursive" : true
}
},
"tuningConfig" : {
"type" : "lucene_index",
"maxRowsPerSegment" : 5000000,
"numShards" : -1,
"overwrite" : false,
"reportParseExceptions" : true,
"writeThreads" : 3,
"writeQueueThreshold" : 1000,
"mergeThreads" : 3,
"useDataSequenceMode" : false,
"maxSegmentIdleSeconds" : 10
}
},
"writerConfig" : {
"type" : "lucene",
"maxBufferedDocs" : -1,
"ramBufferSizeMB" : 16.0,
"indexRefreshIntervalSeconds" : 6
},
"context" : {
"debug" : true
}
}
参数说明:
| 属性名 | 值 | 类型 | 是否必需 | 默认值 | 说明 |
|---|---|---|---|---|---|
| type | lucene_index | string | 是 | - | 指定接入类型,固定 |
| worker | 自定义 | string | 否 | - | 指定启动task的worker地址,前置条件参考配置worker策略 |
| spec.dataSchema | 参见DataSchema | json | 是 | - | 定义表结构和数据粒度 |
| spec.ioConfig | 参见luceneIndexIOConfig | json | 是 | - | 定义数据来源 |
| spec.tuningConfig | 参见luceneIndexTuningConfig | json | 是 | - | 配置Task的优化参数 |
| writerConfig | 参见WriterConfig | json | 是 | - | 配置数据段的写入参数 |
| context | 自定义 | json | 否 | null | 配置Task的上下文环境参数 |
1.1 配置worker策略
worker分配策略支持以下几种:
- fillCapacity: 填充满一个worker容量优先
- fillCapacityWithAffinity: 支持配置数据源与worker的绑定关系,若不绑定,则采用填充满一个worker容量优先
- equalDistribution: 平均分配
- equalDistributionWithAffinity: 支持配置数据源与worker的绑定关系,若不绑定,则平均分配
- javascript: js自定义分配
specialEqualDistribution: 支持指定worker,若不指定,则平均分配
task在worker上的分配策略默认为
equalDistribution均分策略,若要支持指定worker,需要发送以下命令:curl -X 'POST' -H 'Content-Type:application/json' -d '{"selectStrategy":{"type":"specialEqualDistribution"},"autoScaler":null}' http://{overlordIP}:8090/druid/indexer/v1/worker
2. tsv文件导入
TSV文件导入流程大体与CSV文件导入一样,此处不做赘述。仅提供接入的json样例
tsv-task-spec.json详细配置如下:
{
"type" : "lucene_index",
"spec" : {
"dataSchema" : {
"dataSource" : "test_10million",
"parser": {
"type": "string",
"parseSpec": {
"format": "tsv",
"timestampSpec": {
"column": "dealtime",
"format": "yy-MM-dd HH:mm:ss.SSS"
},
"dimensionsSpec": {
"dimensionExclusions": [],
"spatialDimensions": [],
"dimensions": [
{
"name": "old_card_no",
"type": "string"
},
{
"name": "gender",
"type": "string"
},
{
"name": "birthday",
"type": "string"
},
{
"name": "mobile_province",
"type": "string"
},
{
"name": "mobile_city",
"type": "string"
}
]
},
"delimiter": "\t",
"listDelimiter": "\u0002",
"nullFormat": "",
"columns": [
"dealtime",
"old_card_no",
"gender",
"birthday",
"mobile_province",
"mobile_city"
]
}
},
"granularitySpec" : {
"type" : "uniform",
"segmentGranularity" : "MONTH",
"intervals" : ["1000/3000"]
}
},
"ioConfig" : {
"type" : "lucene_index",
"firehose" : {
"type" : "local",
"baseDir" : "/tmp/test/aaa",
"filter" : "*",
"recursive" : true
}
},
"tuningConfig" : {
"type" : "lucene_index",
"maxRowsPerSegment" : 5000000,
"numShards" : -1,
"overwrite" : false,
"reportParseExceptions" : true,
"writeThreads" : 3,
"writeQueueThreshold" : 1000,
"mergeThreads" : 3,
"useDataSequenceMode" : false,
"maxSegmentIdleSeconds" : 10
}
},
"writerConfig" : {
"type" : "lucene",
"maxBufferedDocs" : -1,
"ramBufferSizeMB" : 16.0,
"indexRefreshIntervalSeconds" : 6
},
"context" : {
"debug" : true
}
}
参数说明:
| 属性名 | 值 | 类型 | 是否必需 | 默认值 | 说明 |
|---|---|---|---|---|---|
| type | lucene_index | string | 是 | - | 指定接入类型,固定 |
| spec.dataSchema | 参见DataSchema | json | 是 | - | 定义表结构和数据粒度 |
| spec.ioConfig | 参见luceneIndexIOConfig | json | 是 | - | 定义数据来源 |
| spec.tuningConfig | 参见luceneIndexTuningConfig | json | 是 | - | 配置Task的优化参数 |
| writerConfig | 参见WriterConfig | json | 是 | - | 配置数据段的写入参数 |
| context | 自定义 | json | 否 | null | 配置Task的上下文环境参数 |
3. hdfs文件导入
本节主要说明导入hdfs集群上的文本文件,注意需要保证Tindex集群中的MiddleManager节点与目标hdfs集群是可访问的。
hdfs-task-spec.json详细配置如下:
{
"type" : "lucene_index",
"spec" : {
"dataSchema" : {
"dataSource" : "test_10million",
"parser": {
"type": "string",
"parseSpec": {
"format": "tsv",
"timestampSpec": {
"column": "dealtime",
"format": "yy-MM-dd HH:mm:ss.SSS"
},
"dimensionsSpec": {
"dimensionExclusions": [],
"spatialDimensions": [],
"dimensions": [
{
"name": "old_card_no",
"type": "string"
},
{
"name": "gender",
"type": "string"
},
{
"name": "birthday",
"type": "string"
},
{
"name": "mobile_province",
"type": "string"
},
{
"name": "mobile_city",
"type": "string"
}
]
},
"delimiter": "\u0001",
"listDelimiter": "\u0002",
"nullFormat": "",
"columns": [
"dealtime",
"old_card_no",
"gender",
"birthday",
"mobile_province",
"mobile_city"
]
}
},
"granularitySpec" : {
"type" : "uniform",
"segmentGranularity" : "MONTH",
"intervals" : ["1000/3000"]
}
},
"ioConfig" : {
"type" : "lucene_index",
"firehose" : {
"type" : "hdfs",
"baseDir" : "/tmp/csv",
"filter" : "*.*",
"dirFilter" : null,
"recursive" : true
}
},
"tuningConfig" : {
"type" : "lucene_index",
"maxRowsPerSegment" : 5000000,
"numShards" : -1,
"overwrite" : false,
"reportParseExceptions" : true,
"writeThreads" : 3,
"writeQueueThreshold" : 1000,
"mergeThreads" : 3,
"useDataSequenceMode" : false,
"maxSegmentIdleSeconds" : 10
}
},
"writerConfig" : {
"type" : "lucene",
"maxBufferedDocs" : -1,
"ramBufferSizeMB" : 16.0,
"indexRefreshIntervalSeconds" : 6
},
"context" : {
"debug" : true
}
}
参数说明:
| 属性名 | 值 | 类型 | 是否必需 | 默认值 | 说明 |
|---|---|---|---|---|---|
| type | lucene_index | string | 是 | - | 指定接入类型,固定 |
| spec.dataSchema | 参见DataSchema | json | 是 | - | 定义表结构和数据粒度 |
| spec.ioConfig | 参见luceneIndexIOConfig | json | 是 | - | 定义数据来源 |
| spec.tuningConfig | 参见luceneIndexTuningConfig | json | 是 | - | 配置Task的优化参数 |
| writerConfig | 参见WriterConfig | json | 是 | - | 配置数据段的写入参数 |
| context | 自定义 | json | 否 | null | 配置Task的上下文环境参数 |
4. parquet文件导入
本节主要说明该直接导入hdfs集群上的parquet文件,注意需要保证Tindex集群中的MiddleManager节点与目标hdfs集群是可访问的。
parquet-task-spec.json详细配置如下:
{
"type" : "lucene_index",
"spec" : {
"dataSchema" : {
"dataSource" : "test_10million",
"parser": {
"type": "parquet",
"parseSpec": {
"format": "parquet",
"timestampSpec": {
"column": "dealtime",
"format": "yy-MM-dd HH:mm:ss.SSS"
},
"dimensionsSpec": {
"dimensionExclusions": [],
"spatialDimensions": [],
"dimensions": [
{
"name": "old_card_no",
"type": "string"
},
{
"name": "gender",
"type": "string"
},
{
"name": "birthday",
"type": "string"
},
{
"name": "mobile_province",
"type": "string"
},
{
"name": "mobile_city",
"type": "string"
}
]
},
"delimiter": "\u0001",
"listDelimiter": "\u0002",
"nullFormat": "",
"columns": [
"dealtime",
"old_card_no",
"gender",
"birthday",
"mobile_province",
"mobile_city"
]
}
},
"granularitySpec" : {
"type" : "uniform",
"segmentGranularity" : "MONTH",
"intervals" : ["1000/3000"]
}
},
"ioConfig" : {
"type" : "lucene_index",
"firehose" : {
"type" : "parquet",
"baseDir" : "/tmp/csv",
"filter" : "*.parq",
"dirFilter" : null,
"recursive" : true
}
},
"tuningConfig" : {
"type" : "lucene_index",
"maxRowsPerSegment" : 5000000,
"numShards" : -1,
"overwrite" : false,
"reportParseExceptions" : true,
"writeThreads" : 3,
"writeQueueThreshold" : 1000,
"mergeThreads" : 3,
"useDataSequenceMode" : false,
"maxSegmentIdleSeconds" : 10
}
},
"writerConfig" : {
"type" : "lucene",
"maxBufferedDocs" : -1,
"ramBufferSizeMB" : 16.0,
"indexRefreshIntervalSeconds" : 6
},
"context" : {
"debug" : true
}
}
参数说明:
| 属性名 | 值 | 类型 | 是否必需 | 默认值 | 说明 |
|---|---|---|---|---|---|
| type | lucene_index | string | 是 | - | 指定接入类型,固定 |
| spec.dataSchema | 参见DataSchema | json | 是 | - | 定义表结构和数据粒度 |
| spec.ioConfig | 参见luceneIndexIOConfig | json | 是 | - | 定义数据来源 |
| spec.tuningConfig | 参见luceneIndexTuningConfig | json | 是 | - | 配置Task的优化参数 |
| writerConfig | 参见WriterConfig | json | 是 | - | 配置数据段的写入参数 |
| context | 自定义 | json | 否 | null | 配置Task的上下文环境参数 |